OpenAI lança novos modelos de áudio para dar mais personalidade aos agentes de IA

A OpenAI lançou novos modelos de áudio text-to-speech e speech-to-text que rodam em API, facilitando a vida dos desenvolvedores que querem criar um assistente de IA com uma voz com mais personalidade.
O tom e estilo das vozes podem ser personalizados pelo modelo gpt-4o-mini-tts, garantindo que elas tenham personalidade própria. A OpenAI diz que, pela primeira vez, os desenvolvedores podem usar o modelo text-to-speech para criar assistentes que falam de uma forma específica, com comandos como “fale como um técnico de esportes”, “fale de forma simpática”ou até mesmo “fale como um pirata”.
Os novos recursos funcionam em vários idiomas, e já podem ser integrados aos agentes de IA e outros modelos de IA da empresa. Assim, os desenvolvedores já podem começar a integrarem essas vozes hoje mesmo em seus projetos.
O novo modelo de áudio speech-to-text gpt-4o-transcribe da OpenAI entende melhor nuances como diferentes sotaques, o que aumenta a precisão dos resultados, reduzindo erros de entendimento. Além disso, ele está mais adaptado a ambientes barulhentos e variações na velocidade das vozes.
Em resumo, com essas melhorias, a OpenAI diz que eles passam a funcionar melhor para uso em call centers, transcrições de reuniões e mais.
Teste agora mesmo os novos modelos de áudio da OpenAI
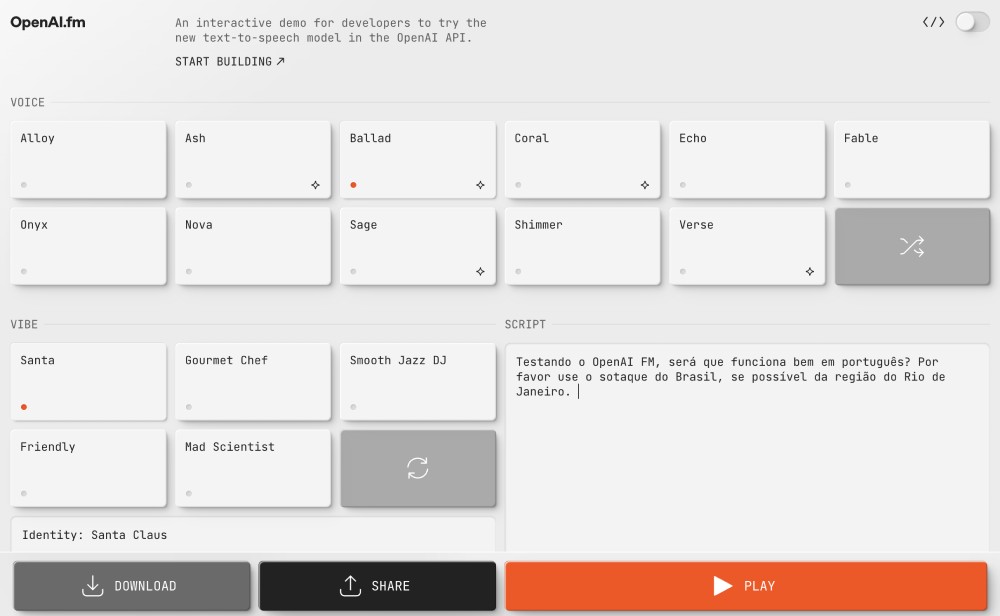
Outra novidade bem divertida é o OpenAI FM, uma demo interativa na qual você pode testar diferentes vozes e estilos, confira aqui. Eu pedi a ele para fazer diferentes sotaques do Brasil e ele funcionou direitinho, pelo menos com os mais conhecidos.
Para quem quiser testar os novos modelos de áudio da OpenAI mais a fundo, eles já estão disponíveis via API. Só resta saber como eles irão se sair na comparação com concorrentes especializados como a ElevenLabs e a Sesame.
Saiba mais sobre os novos modelos de áudio no site da OpenAI.





